How will AI become not only a faithful assistant but also a headache for companies
Recently, the National Cyber Security Centre published a report on the impact of AI on cyber threats in the next two years.
What is important to emphasize from this report?

-
1. Most cybercriminals already use AI in some way in their activities.
-
2. Cyberattacks using AI are generally more effective and harder to detect.
-
3. In the coming years, existing attacks will evolve and become more sophisticated. Artificial intelligence will help analyze data breaches faster and more efficiently, which can then be used to train AI models.
-
4. Artificial intelligence will lower the barrier for entry into the profession for novice cybercriminals. This may lead to a trend of increasing information extortion in the coming years.
But there is also good news!
If cybercriminals are improving their AI skills, nothing stops us from doing the same.
Experts from the National Cyber Security Centre believe that more sophisticated uses of AI in cyber operations are highly likely to be restricted to threat actors with access to quality training data, significant expertise, and resources.
It is necessary to continue monitoring the development of this technology and work on improving mechanisms for protection against AI-based cyber attacks. Let's not forget to keep our finger on the pulse. We have time to become more advanced and stay one step ahead in this AI race.

Read more interesting articles and news from
the world of Artificial Intelligence on our LinkedIn page
Read more
Machine learning principles. Secure deployment

Content
In today's article, we will discuss the third section of
the National Cyber Security Centre publication "Secure Deployment". It will cover the principles of protection during the deployment phase of ML systems, including protection against evasion attacks, model extraction attacks, model inversion attacks, data extraction attacks, and availability attacks.
Protect information that could be used to attack your model
Knowledge of the model can help attackers organize a more effective attack. This knowledge ranges from "open box," where the attacker has complete information about your model, to "closed box," where the attacker can only query the model and analyze its output. Many attacks on ML models depend on the model's outputs given certain inputs. More detailed outputs increase the likelihood of a successful attack.
What can help implement this principle?
-
Ensure your model is appropriately protected for your security requirements
The model should provide only the necessary outputs to reduce the risk of attacks. Some attacker techniques may use the model's outputs to organize attacks, even though this is technically challenging. The increasing popularity of LLMs has revived prompt injection attacks. Limiting what can be input as a prompt can help but does not eliminate the possibility of an attack. It is recommended to implement access control to restrict access levels based on user authorization.
-
Use access controls across different levels of detail from model outputs
It is necessary to define the level of detail for each user. It is important to present information in a way that allows them to quickly assess system behavior without accessing detailed output information. There are two popular solutions for access control: Role-Based Access Control (RBAC) and Attribute-Based Access Control (ABAC).
It is advisable to restrict access to high-precision outputs only for certain authorized users (e.g., trusted developers). For roles requiring transparency, it is better to display data in summary or graphical format. If access to precise values is necessary, consider options with lower precision or slower data transmission. Configuration settings should be evaluated based on their benefits and associated security risks, with the most secure configuration embedded in the system as the only option.
Monitor and log user activity
Analyzing user queries to the model and identifying unusual behavior helps prevent attacks. Many of them occur through repeated requests at a rate not typical for ordinary users.
With the rise in popularity of LLMs, prompt injection attacks have emerged that allow bypassing API restrictions and interacting with models in unintended ways.
What can help implement this principle?
Consider automated monitoring of user activity and logs
A key point is understanding the differences between suspicious and expected behavior. The criteria for "suspicious" behavior vary for each system and should be based on its intended purpose.
With SAF tools, you can analyze user behavior, navigate through event flows, and customize actions for critical metrics quickly and conveniently. This is clearly demonstrated
in this article.
You can find previous reviews of other sections of the article below ⬇️
Machine learning principles. Secure design
Content
The National Cyber Security Centre has published
a comprehensive article on the principles that help make informed decisions regarding the design, development, deployment, and operation of machine learning (ML) systems. Today, we will look at the first section, "Secure Design," and share with you a concise summary of the principles at the design stage of the ML system development lifecycle.
Raise awareness of ML threats and risks
Security in design is quite resource-intensive. However, applying this approach from the beginning of the system's lifecycle can save a significant amount of funds on various reworks and fixes in the future. It is essential to ensure protection at every stage of the development lifecycle.
What can help implement this principle?
-
Provide guidance on the unique security risks facing AI systems
It is necessary for developers' knowledge in the field of ML to always be up-to-date. For example, it is important to be aware of the types of threats that their systems may be exposed to: Evasion attacks, Poisoning attacks, Privacy attacks, and others.
-
Enable and encourage a security-centered culture
Developers are not always security experts, but if they understand how their solutions impact the system's vulnerability, it will ultimately be crucial. Therefore, it is important to promote collaboration with security experts and the sharing of knowledge and experience.
Model the threats to your system
It is very challenging to guarantee complete security against constantly evolving attacks from malicious actors. Therefore, it is important to understand how an attack on a specific ML component can affect the system as a whole.
What can help implement this principle?
-
Create a high-level threat model for the ML system
You can create a high-level threat model to gain an initial understanding of the broader systemic consequences of any attack on your ML component. Assess the implications of ML security threats and model the failure modes of the entire system.
Use CIA (confidentiality, integrity, availability) and a high-level threat model to explore the system.
-
Model wider system behaviors
When developing a system, it is important to combine knowledge and experience in ML, knowledge about the system, and an understanding of the limitations of ML components. It is advisable to use multi-layered countermeasures to authenticate requests and detect suspicious activity, including logic-based and rule-oriented controls outside the model. User access should also be considered: open web systems require stricter protective measures compared to closed systems with controlled access.
Minimise an adversary's knowledge
There is a practice of disclosing information after an attack, which undoubtedly benefits the entire ML community and helps enhance ML security across the industry. However, reconnaissance is often the first stage of an attack, and excessive publication of information regarding model performance, architectures, and training data can facilitate attackers in developing their attacks.
When deciding on disclosure, it is important to consider the balance between the motivation for sharing (marketing, publications, or improving security practices) and protecting key details of the system and model.
What can help implement this principle?
Analyze vulnerabilities against inherent ML threats
Identifying specific vulnerabilities in workflows or algorithms during the design phase helps reduce the need for remediation in the system. The significance of vulnerabilities depends on factors such as data sources, data sensitivity, the deployment and development environment, and the potential consequences for the system in case of failure. It is recommended to regularly analyze decisions made during the development process and conduct a formal security review before deploying the model or system into production.
What can help implement this principle?
-
Implement red teaming
Simulating the actions of an attacker to identify system vulnerabilities, or what is commonly referred to as applying a "red teaming mindset" on a regular basis, helps define security requirements and determine design solutions.
-
Consider automated testing
It is advisable to use automated tools to assess and test the security of the model against known vulnerabilities and attack methods. Additionally, keep an eye on new standards that may emerge in this area, paying attention to guidance from the AI Standards Hub dedicated to the standardization of AI technologies.
The NCSC article also provides examples of open-source tools for assessing reliability.
In upcoming articles, we will cover the next sections of the article: secure development, secure deployment, and secure operation. So don’t go too far! In the meantime, feel free to explore other articles from SAF 😉
Read more
Machine learning principles. Secure development
Content
We continue to analyze
the article from the National Cyber Security Centre on principles that help make informed decisions about the design, development, deployment, and operation of machine learning (ML) systems. Let’s move on to the second section, "Secure Development".
Secure Your Supply Chain
The ML model depends on the quality of the data it is trained on. The process of collecting, cleaning, and labeling data is costly. Often, people use third-party datasets, which carry certain risks.
Data may be poorly labeled or intentionally corrupted by malicious actors (this method is known as "data poisoning"). Training a model on such corrupted data can lead to a deterioration in its performance with serious consequences.
What can help implement this principle?
-
Verify any third-party inputs are from sources you trust
When acquiring assets (models, data, software components), it is important to consider supply chain security. Be aware of your suppliers' security levels and inform them of your security requirements. Understanding external dependencies will simplify the process of identifying vulnerabilities and risks.
-
Use untrusted data only as a last resort
If you must use "untrusted" data, keep in mind that methods for detecting poisoned instances in datasets have mostly been tested in academic settings and should only be applied as a last resort. It is important to carefully assess their applicability and impact on the system and development process.
-
Consider using synthetic data or limited data
There are several techniques for training ML systems on limited data instead of using untrusted sources. However, these methods come with their own challenges:
- Generative adversarial networks (GANs) can enhance and recreate statistical distributions of the original data.
- Game engines can introduce specific characteristics.
- Data augmentation is limited to manipulating only the original dataset.
-
Reduce the risk of insider attacks on datasets from intentional mislabeling
The level of scrutiny for labelers should correspond to the seriousness of the consequences that incorrect labeling may have. Industry security and personnel vetting recommendations can assist with this. If labeler vetting is not possible, use processes that limit the impact of a single labeler, such as segmenting the dataset so that one labeler does not have access to the entire set.
Secure Your Development Infrastructure
The security of the infrastructure is especially important in ML, as a compromise at this stage can affect the entire lifecycle of the system. It is essential to keep software and operating systems up to date, restrict access only to those who have permission, and maintain records and monitoring of access and changes to components.
What can help implement this principle?
-
Follow Cyber Security Best Practices and Recognized IT Security Standards
Adhering to cyber security best practices is not limited to ML development. Key measures include protecting data at rest and in transit, updating software, implementing multi-factor authentication, maintaining security logs, and using dual control. Pay attention to the globally recognized standard ISO/IEC 27001, which offers a comprehensive approach to managing cyber risks.
-
Use Secure Software Development Practices
Secure software development practices help protect the development lifecycle and enhance the security of your machine learning models and systems. It is important to track common vulnerabilities associated with the software and code libraries being used.
-
Be Aware of Legal and Regulatory Requirements
Ensure that decision-makers are aware of the composition of your data and the legal regulations regarding its collection. It is also important for your developers to understand the consequences of data breaches, their responsibilities when handling information, and the necessity of creating secure software.
Manage the Full Life Cycle of Models and Datasets
Data is the foundation for developing ML models and influences their behavior. Changes to the dataset can undermine the integrity of the system. However, during the model development process, both data and models often change, making it difficult to identify malicious alterations.
Therefore, it is important for system owners to implement a monitoring system that records changes to assets and their metadata throughout the entire lifecycle. Good documentation and monitoring help effectively respond to instances of data or model compromise.
What can help implement this principle?
-
Use version-control tools to track and control changes to your software, dataset, and resulting model.
-
Use a standard solution for documenting and tracking your models and data.
-
Track dataset metadata in a format that is readable by humans and can be processed/parsed by a computer.
To track datasets, you can use a data catalog or integrate them into larger solutions such as a data warehouse. The necessary metadata composition depends on the specific application and may include: a description of data collection, sensitivity level, key metrics, dataset creator, intended use and restrictions, retention time, destruction methods, and aggregated statistics.
-
Track model metadata in a format that is readable by humans and can be processed/parsed by a computer.
For security purposes, it is useful to track the following metadata:
- The dataset on which the model was trained.
- The creator of the model and contact information.
- The intended use case and limitations of the model.
- Secure hashes or digital signatures of the trained models.
- Retention time for the dataset.
- Recommended method for disposing of the model.
Storing model cards in an indexed format facilitates the search and comparison of models for developers.
-
Ensure each dataset and model has an owner.
Development teams should include roles responsible for managing risks and digital assets. Each created artifact should have an owner who ensures secure management of its lifecycle. Ideally, this should be a person involved in creating the asset, with contact information recorded in the metadata while considering personal information security.
Choose a Model that Maximizes Security and Performance
When selecting a model, it is important to consider both security and performance. An inappropriate model can lead to decreased performance and vulnerabilities. The feasibility of using external pre-trained models should be assessed. At first glance, their use seems appealing due to reduced technical and economic costs. However, they come with their own risks and can make your system vulnerable.
What can help implement this principle?
-
Consider a Range of Model Types on Your Data
Evaluate the performance of various architectures, starting with classical ML and interpretable methods before moving on to modern deep learning models. The choice of model should be based on the task requirements, without bias towards new algorithms.
-
Consider Supply Chain Security When Choosing Whether to Develop In-House or Use External Components
Use pre-trained models only from trusted sources and apply vulnerability scanning tools to check for potential threats.
-
Review the Size and Quality of Your Dataset Against Your Requirements
Key metrics for assessing dataset quality include completeness, relevance, consistency, integrity, and class balance. If there is insufficient data to train the model, additional data can be collected, transfer learning can be utilized, existing data can be augmented, or synthetic data can be generated. It is also beneficial to choose an algorithm that works well with limited data.
-
Consider Pruning and Simplifying Your Model During the Development Process
Simple models can be quite effective, but there are methods for reducing the size of complex neural network models. Most of these fall under the category of "pruning" — removing unnecessary neurons or weights after training. However, this can affect performance and is primarily studied in academic settings.
Halfway through, we have two sections left to cover: secure deployment and secure operation. If you haven't read the article on secure design yet, we recommend doing so as soon as possible!
Read about secure design
Machine learning principles. Secure operation
Content
Here we are at the conclusion of the series of articles
on the principles of the National Cyber Security Centre that help make informed decisions about the design, development, deployment, and operation of machine learning systems. Today, we will discuss the final section, which focuses on recommendations that apply to ML components once they are in operation.
Understand and mitigate the risks of using continual learning (CL)
Using CL is essential for ensuring the safety and performance of the system. It helps address issues such as model drift and erroneous predictions by creating a "moving target" for attackers. However, the process of updating the model based on user data can open new avenues for attacks, as the model's behavior may change under the influence of unreliable sources. Retraining on updated data can lead to the loss of old but correct behaviors of the model. Therefore, after retraining, the model should be treated as new.
What can help implement this principle?
-
Develop effective MLOps so performance targets are achieved before an updated model goes into production
The creation of up-to-date CL models should be an automated process that incorporates best practices in MLOps and appropriate security monitoring. It is important to track data throughout the CL process to identify sources of errors or attacks, as well as to manage model drift when its predictions begin to change due to new data.
Various tools are available for effective MLOps, such as Continuous Machine Learning (CML), Data Version Control (DVC), and MLflow.
It is recommended to use metadata and model parameters as an alert system for significant deviations, which may indicate abnormal or malicious behavior. The frequency of manual testing of model updates will depend on your system and level of risk.
-
Consider using a pipeline architecture with checkpoints for testing
It is advisable to run several models in parallel so that updates and testing occur before deployment. For this, sandboxed environments can be used to compare updated models or organize experimental deployments targeted at small user groups to interact with new models.
-
Capture updates to datasets and models in their associated metadata
During the collection of new data in CL, it is important to consider the same security issues as in the development phase. The reliability of data sources must be assessed: are they trusted users or is access open to all? Follow the recommendations for creating metadata for assets that we discussed
in the previous article.
-
Consider processing data and training locally
If you do not plan to update the central model, CL can be conducted locally on the user's device without leaving it. Techniques such as
federated learning can be used to make local changes to the central model.
Appropriately sanitize inputs to your model in use
Proper sanitization or preprocessing of data can protect the model from attacks using specially crafted inputs. For example, evasion attacks, where minor changes to an image can deceive the model. In this case, simple JPEG compression may help.
If the model is trained on sensitive data, proper sanitization or anonymization can reduce the risk of data extraction and lower the likelihood of attacks. However, CL creates additional challenges for privacy protection, as it requires collecting data directly from users.
What can help implement this principle?
-
Implement tracking and filtering of data
Filters in data collection processes and MLOps help cleanse input data, protecting the model from unwanted or malicious information. It is recommended to use standard transformation sets to unify input data during model retraining.
The necessary filters depend on the type of system and the reliability of data sources. Filtered data will likely require regular human oversight, and the filters themselves will need periodic updates to guard against potential bypasses by attackers.
-
Implement out of distribution detection on model inputs
It is essential to select the best method for out-of-distribution (OoD) detection. Consider using maximum softmax probability and temperature scaling.
For complex models with large feature spaces, it is worth exploring whether you can factor the OoD distance into the model’s confidence scores, which may help in detecting attacks.
-
Use appropriate techniques to anonymise user data
Methods that ensure privacy and reduce security risks include:
- Statistical methods that provide confidentiality without distorting overall statistics.
- Techniques that render data unreadable to humans (e.g., encryption, hashing).
- Data generalization to anonymize individual contributions while preserving overall trends.
- Data swapping between entries while maintaining the underlying statistics of the dataset.
- Removal of attributes to prevent data from being linked to a specific record without additional information.
Develop incident and vulnerability management processes
ML systems, like any other software, are susceptible to vulnerabilities, and having vulnerability management processes helps minimize risks. The rapid development of ML and its integration into critical systems make information sharing about vulnerabilities especially important. Receiving feedback from users about potential vulnerabilities in your products will help address security issues and ensure compliance with legal requirements for safe data handling.
What can help implement this principle?
-
Develop a vulnerability disclosure process for your system and organization
Vulnerabilities are discovered constantly, and security professionals strive to report them directly to the responsible organizations. Such reports help improve system security, as they enable organizations to respond promptly to vulnerabilities, reducing the risk of compromise and reputational damage from public disclosure.
-
Develop a process for responsibly sharing relevant threat intelligence
Share knowledge about cyber threats on specialized platforms. In a previous article, we discussed the benefits and risks of publishing details about your systems. Nonetheless, strive to find ways to share information that will help others in developing secure ML while avoiding the disclosure of critical data.
We have finally covered all the NCSC principles regarding interaction with machine learning. We hope that the information has been helpful and has provided you with a better understanding of the key aspects of ensuring the security and reliability of ML systems.
You can find previous reviews of other sections of the article below ⬇️
Recording of the webinar
2024 State of Data Monitoring

In the webinar we discussed the latest trends in data monitoring and shared our predictions for 2024. We also demonstrated the implementation of these trends in the SAF product using a case study. We would like to thank everyone for their participation and interesting questions.
And for those who could not join us yesterday, we have prepared a recording. You can watch it at:
Watch the recording in Zoom
Timecodes for your convenience
-
01:25
About SAF System
-
02:41
Trends in Data and Analytics 2023-2024
-
06:00
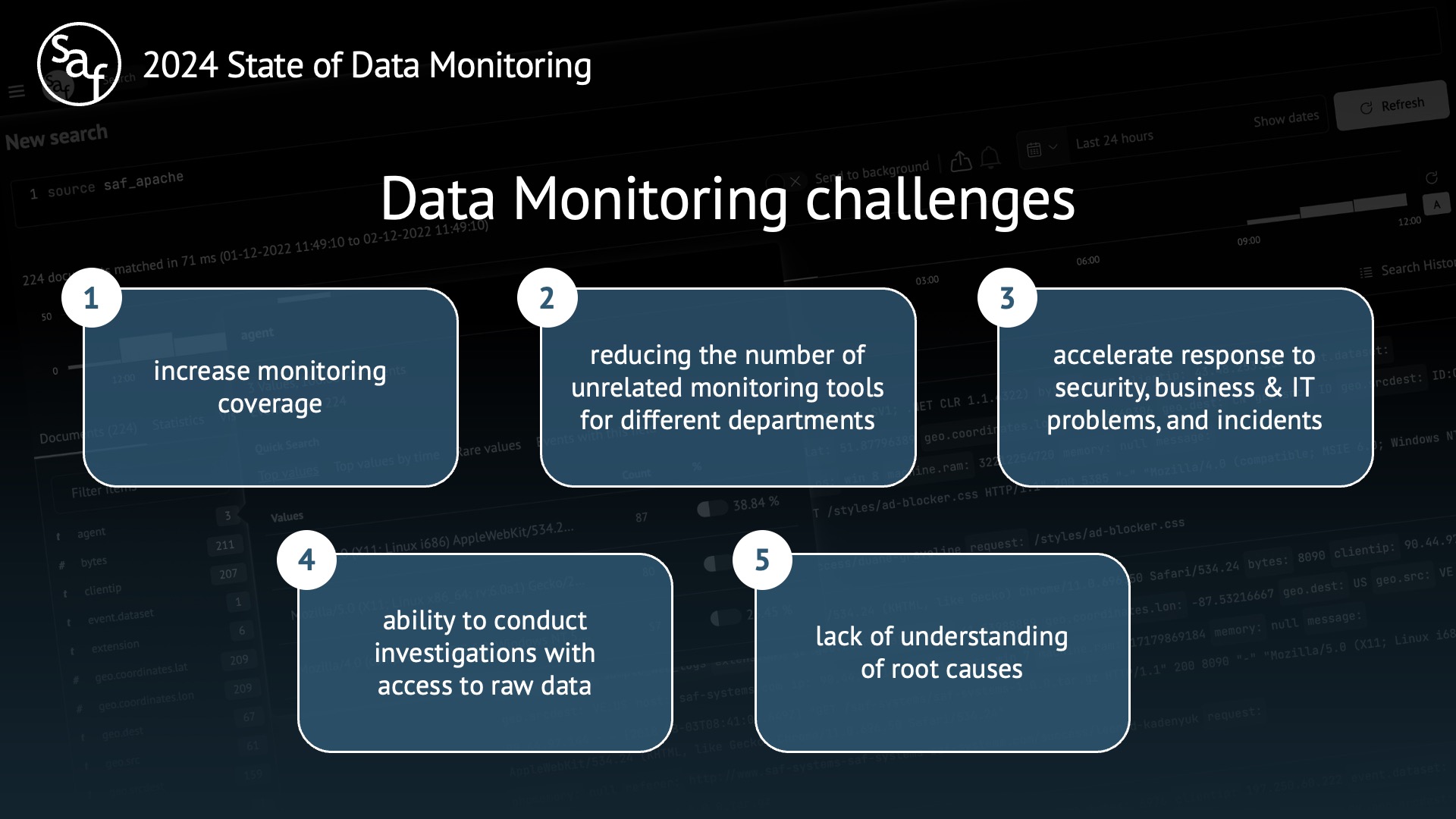
Data Monitoring challenges
-
08:10
About the case
-
10:00
Challenge #1 Cyber Security (Core, Incident Manager, Inventory)
-
17:33
Challenge #2 IT Operations (Core: Dashboards, Asset Service Model)
-
22:25
Challenge #3 Business Intelligence (Core: Search Engine, Dashboards, Asset Service Model)
-
34:55
More cases on our website
-
37:22
Q&A
Some slides from the presentation
We hope you found the webinar useful. Follow our news on LinkedIn and stay up to date with the latest data monitoring trends! 🔥
Follow us
Top Strategic Technology Trends 2024
Content
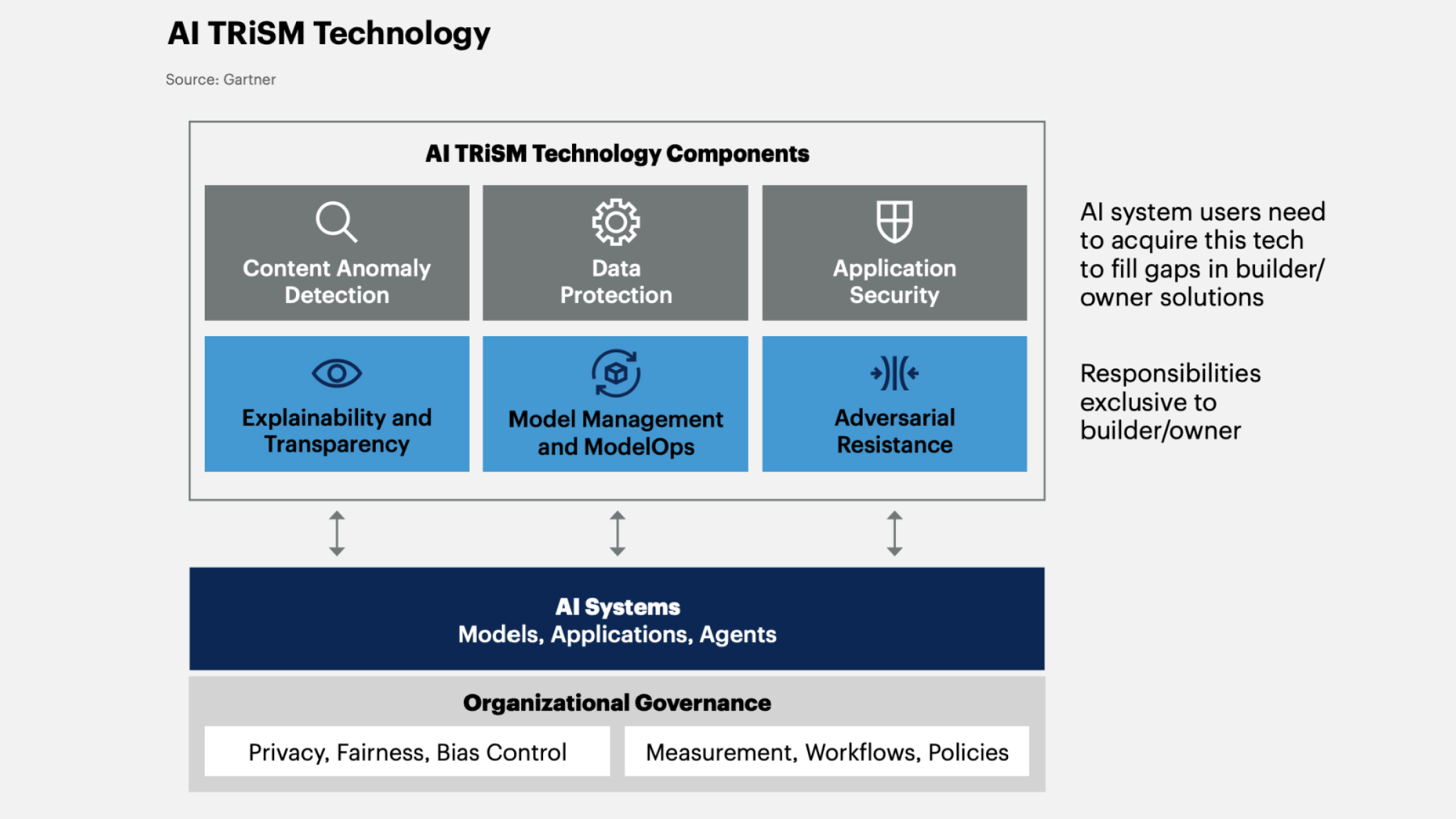
1. AI Trust, Risk and Security Management (AI TRiSM)
AI TRiSM is a concept of artificial intelligence that ensures the AI system is reliable, fair, and secure, while protecting data. Typically, AI TRiSM is used in many artificial intelligence applications to create a safe and dependable environment.
Gartner predicts that by 2026, companies implementing AI TRiSM will enhance decision-making accuracy by eliminating up to 80% of erroneous and unlawful information.
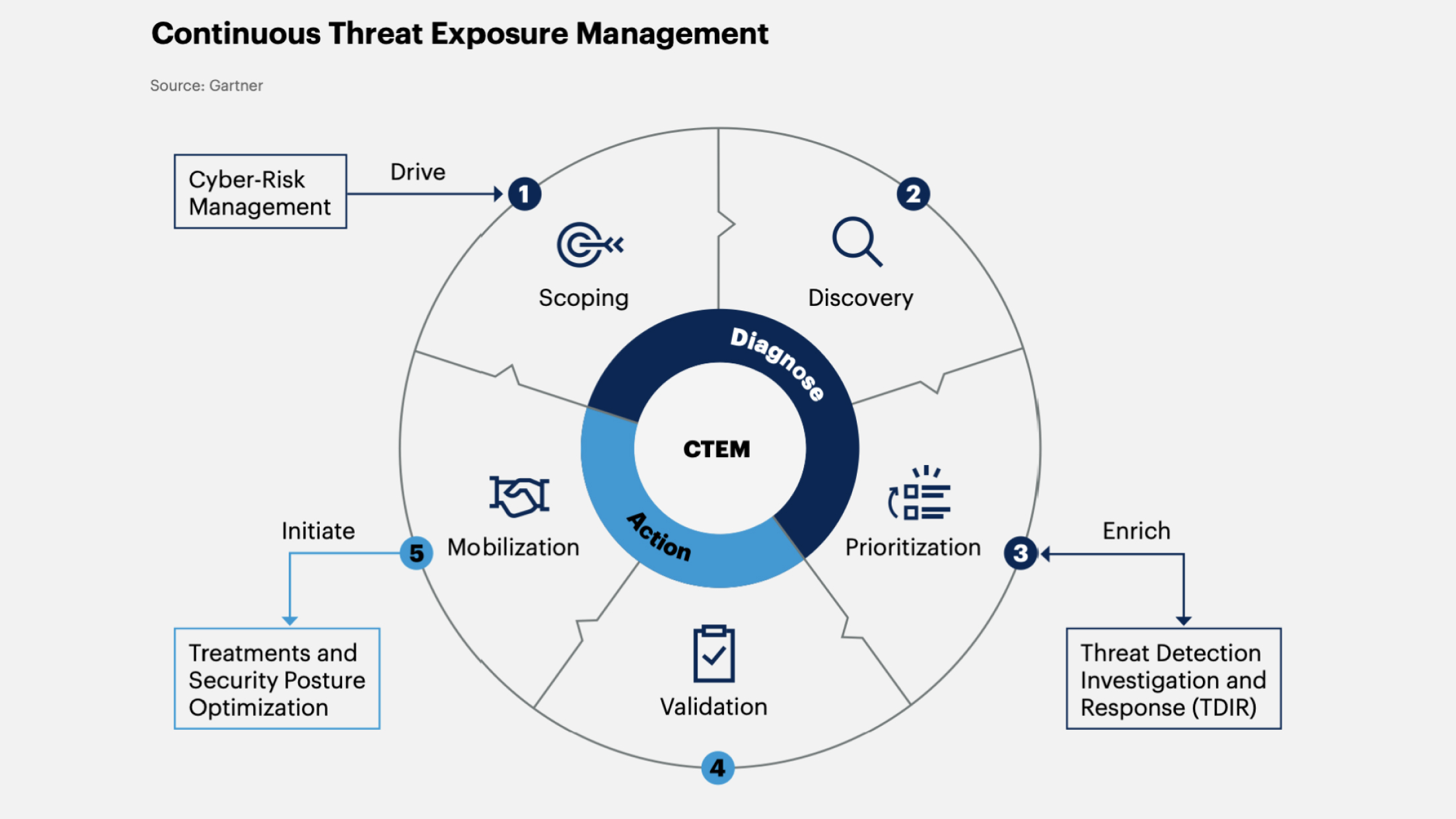
2. Continuous Threat Exposure Management (CTEM)
CTEM helps organizations manage the impact of internal and external threats by identifying, assessing, and minimizing risks. This process includes:
-
Identifying critical assets most vulnerable to cyber attacks.
-
Assessing the likelihood of these assets being attacked.
-
Mitigating risks through the implementation of control measures such as firewalls, intrusion detection systems, security policies, and other countermeasures.
Gartner forecasts that by 2026, organizations prioritizing security investments based on the CTEM program will reduce breaches by two-thirds.
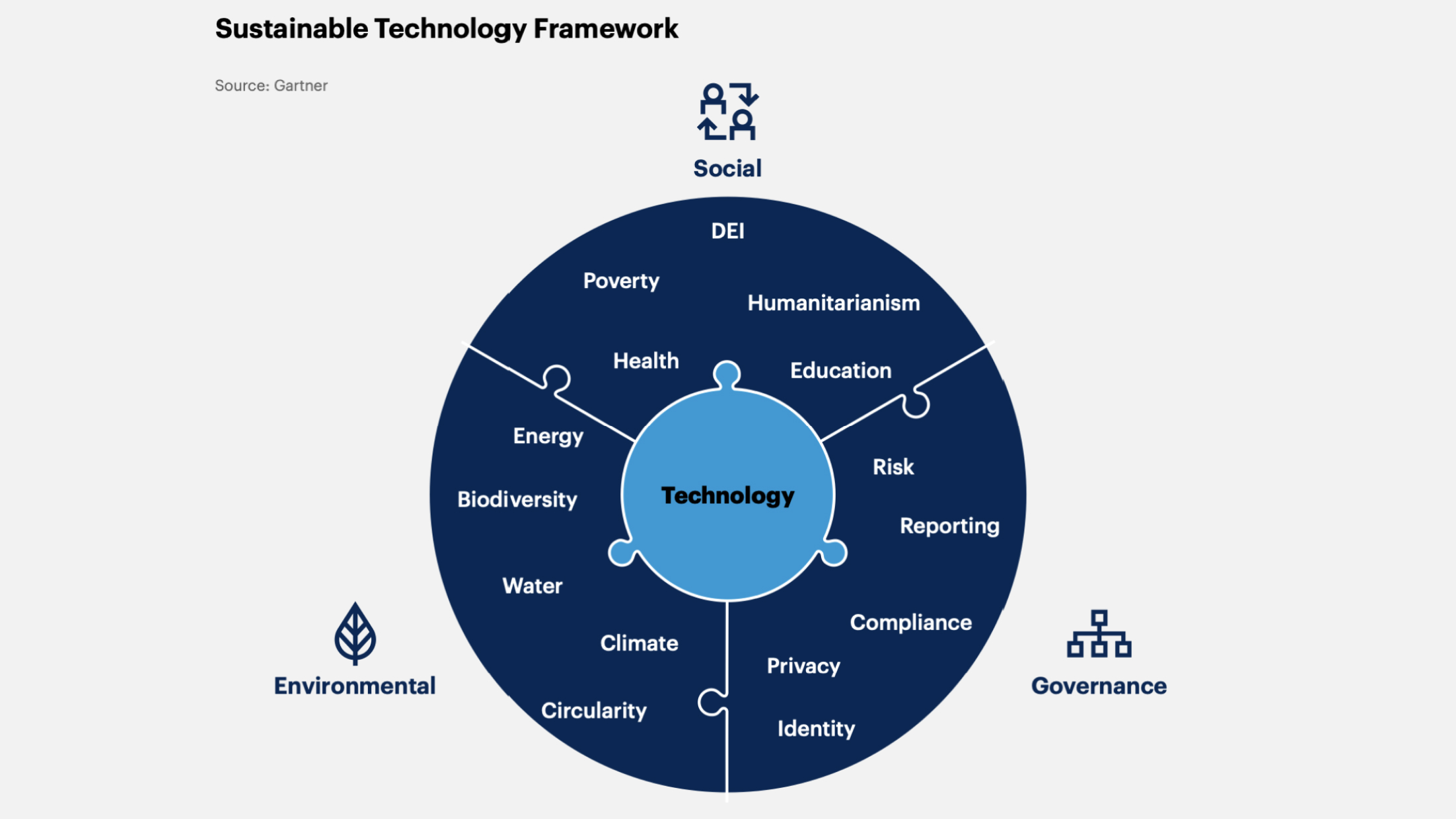
3. Sustainable Technology
This is a system of digital solutions used to ensure:
-
Environmental sustainability.
-
Social responsibility (compliance with labor standards, quality service, safety).
-
Responsible corporate governance (transparency in company operations, customer data protection).
Gartner's forecast: by 2027, 25% of CIOs will have compensation linked to their sustainable technology impact.
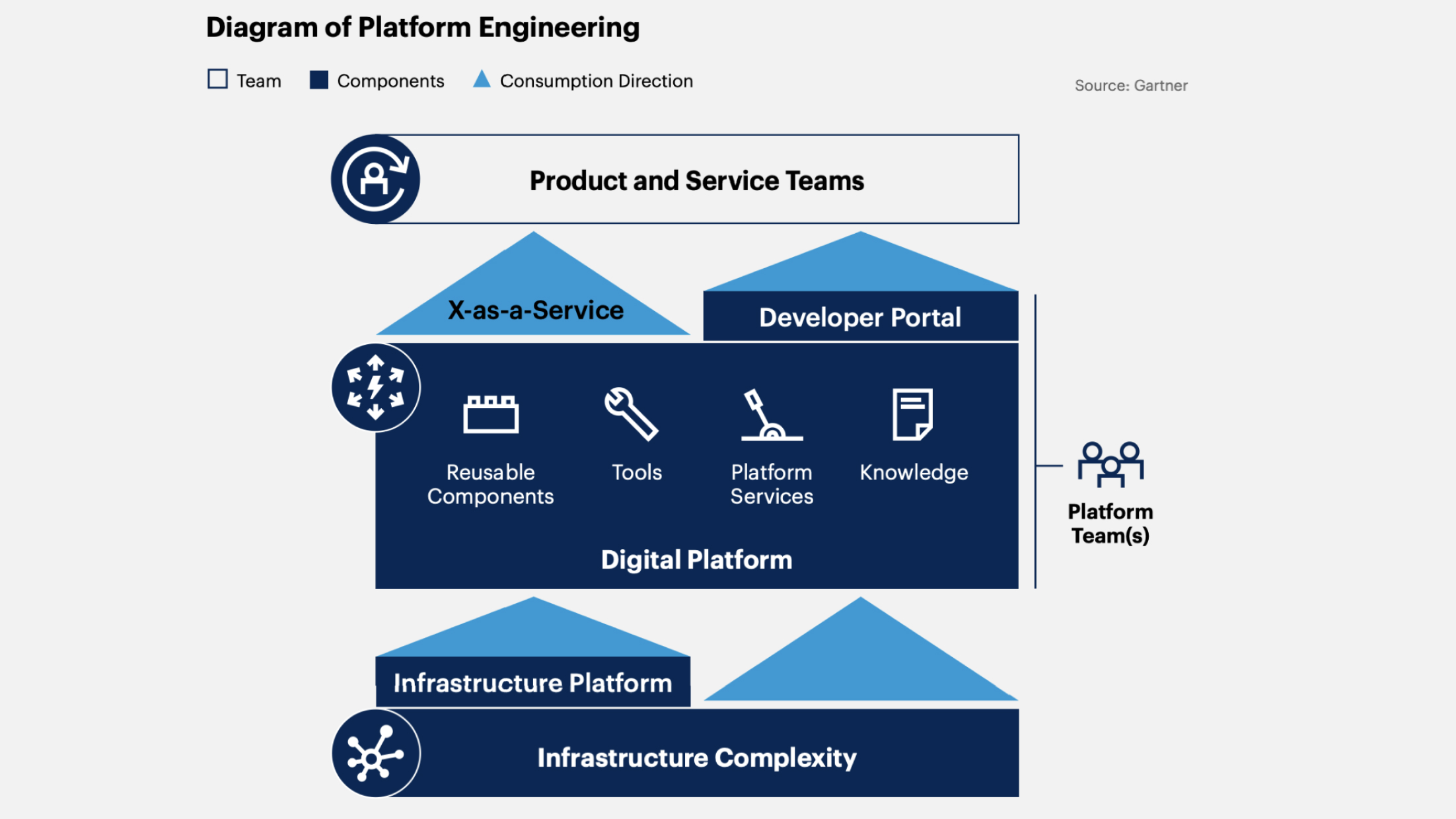
4. Platform Engineering
This is the process of developing and creating platforms that provide infrastructure, tools, and services to support various applications and services. This approach is becoming increasingly popular in the modern software development industry as it significantly simplifies and accelerates the process of creating and supporting applications.
Gartner believes that by 2026, 80% of software development organizations will establish platform development teams as internal providers of reusable services, components, and tools for application delivery.
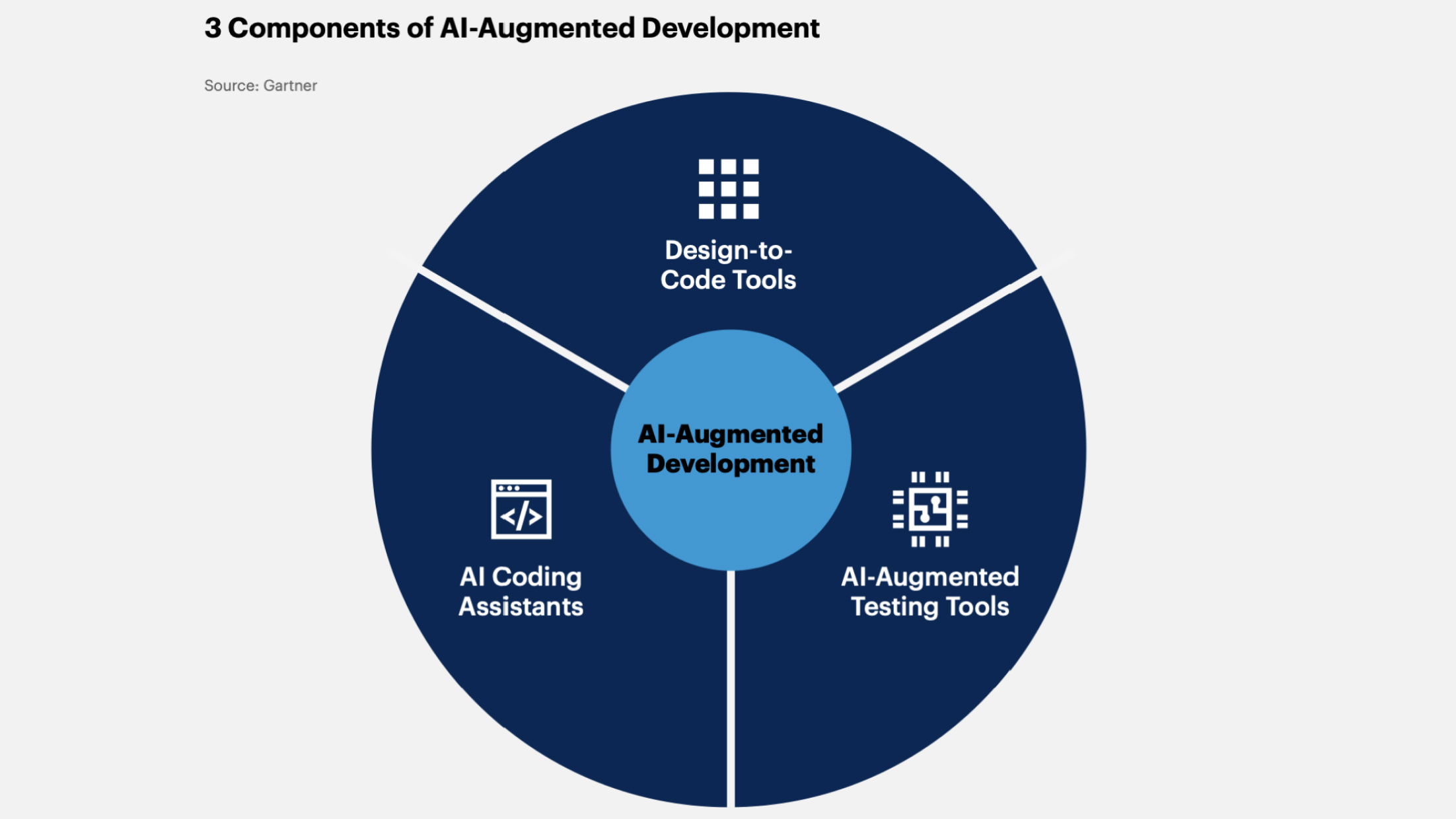
5. AI-Augmented Development
AI tools enable developers to save time on coding, allowing them to focus on more strategic tasks. Therefore, it is not surprising that Gartner predicts that by 2028, 75% of developers will use AI assistants for programming. At the beginning of 2023, their share was less than 10%.
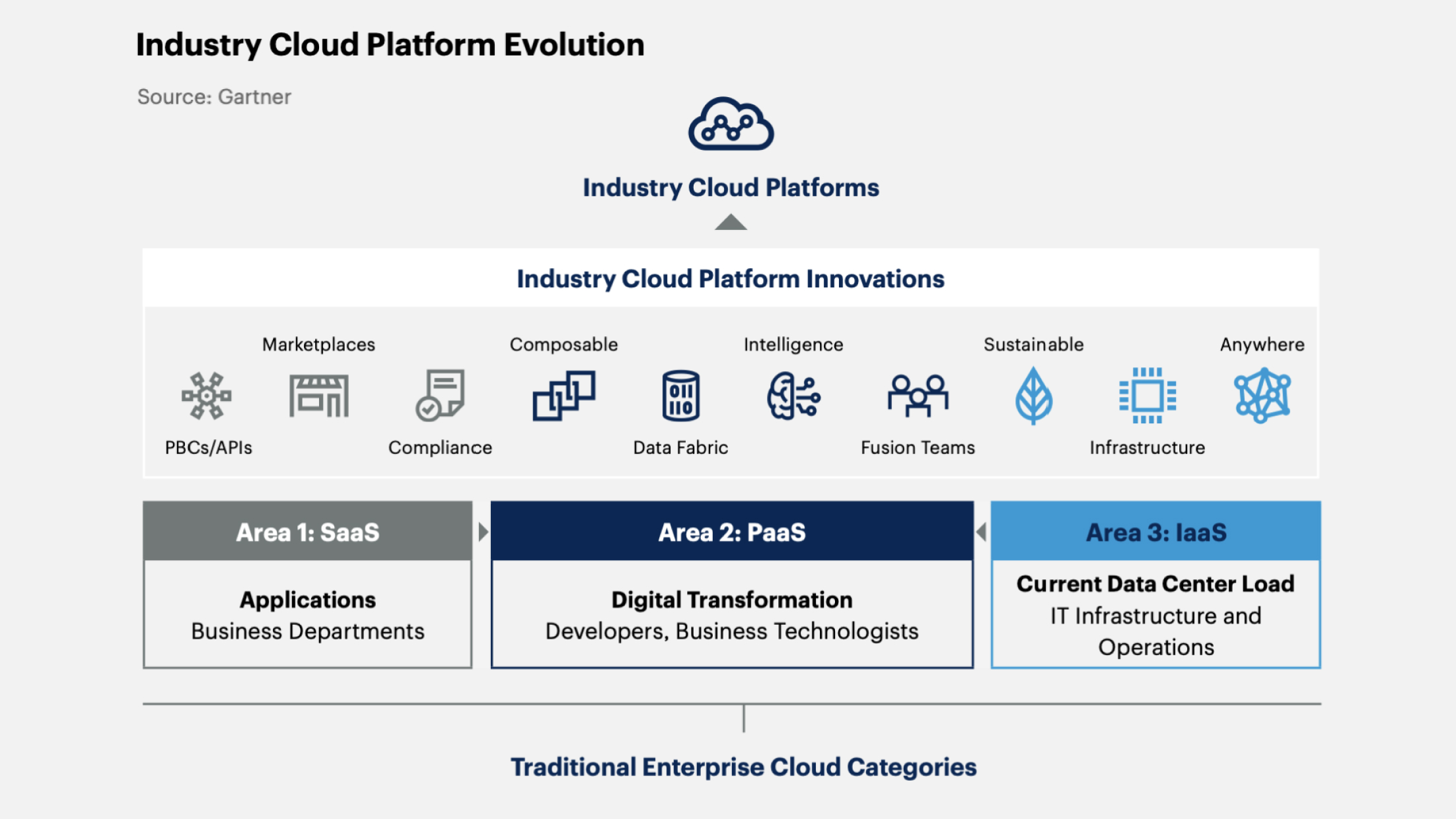
6. Industry Cloud Platforms
These are specialized services tailored to address critical business tasks in specific industries.
Gartner's forecast: by 2027, over 50% of companies will use industry cloud platforms to expedite business initiatives implementation, whereas in 2023 this figure was less than 15%.
7. Intelligent Applications
This refers to consumer or business applications that utilize artificial intelligence methods to perform complex tasks, make forecasts, automate operations, etc.
According to Gartner's predictions, by 2026, 30% of new applications will use AI to launch personalized and adaptive user interfaces. In 2023, their share was only 5%.
8. Democratized Generative AI
Access to GenAI becomes more democratized due to the development of technologies, platforms, and tools that make it accessible and understandable to a wide audience.
Gartner believes that by 2026, over 80% of companies will leverage APIs and generative AI models and/or deploy applications with generative AI in production environments (in 2023, they were less than 5%).
9. Augmented Connected Workforce (ACWF)
ACWF is a concept that combines technologies and methods to enhance the productivity and efficiency of employees. The main idea is to use various innovative technologies (AI, IoT, data analytics, virtual and augmented reality) to create a connected and enhanced work environment.
Gartner Forecast: By 2027, 25% of CIOs will use augmented connected workforce initiatives to reduce time to competency by 50% for key roles.
10. Machine Customers
These are virtual assistants that act on behalf of a customer or organization as economic agents, acquiring goods or services in exchange for payment.
Gartner predicts that by 2028, 20% of digital stores adapted for humans will become outdated due to machine customers.
This is the list of trends provided by Gartner. We have tried to convey all the essential information to you as succinctly as possible without losing the essence. Thanks to AI, our world is changing at a tremendous speed. Therefore, it is crucial not to ignore these trends and gradually integrate them into your company to become even more efficient and reliable.
Want to keep up with the trends with SAF? 🏆
Contact Us
Why does your company need
the SAF Cybersecurity Bundle?
A little bit about Cybersecurity Bundle
-
Perhaps for detecting, investigating, and resolving issues in IT infrastructure and cyber security infrastructure?
-
Maybe for building user visualization based on correlation rules?
-
Or maybe for retrospective search over stored data for artefacts related to a threat-hunting hypothesis?
With the SAF Cybersecurity Bundle, you don't even have to choose - it covers all these needs thanks to its holistic cyber security monitoring and incident management mechanism. Let's experience all the benefits of this bundle through a practical story.

More about the case
So, we present to you a company with the code name Jolly Meal. It is one of the fast-developing B2C companies with a goods delivery service.

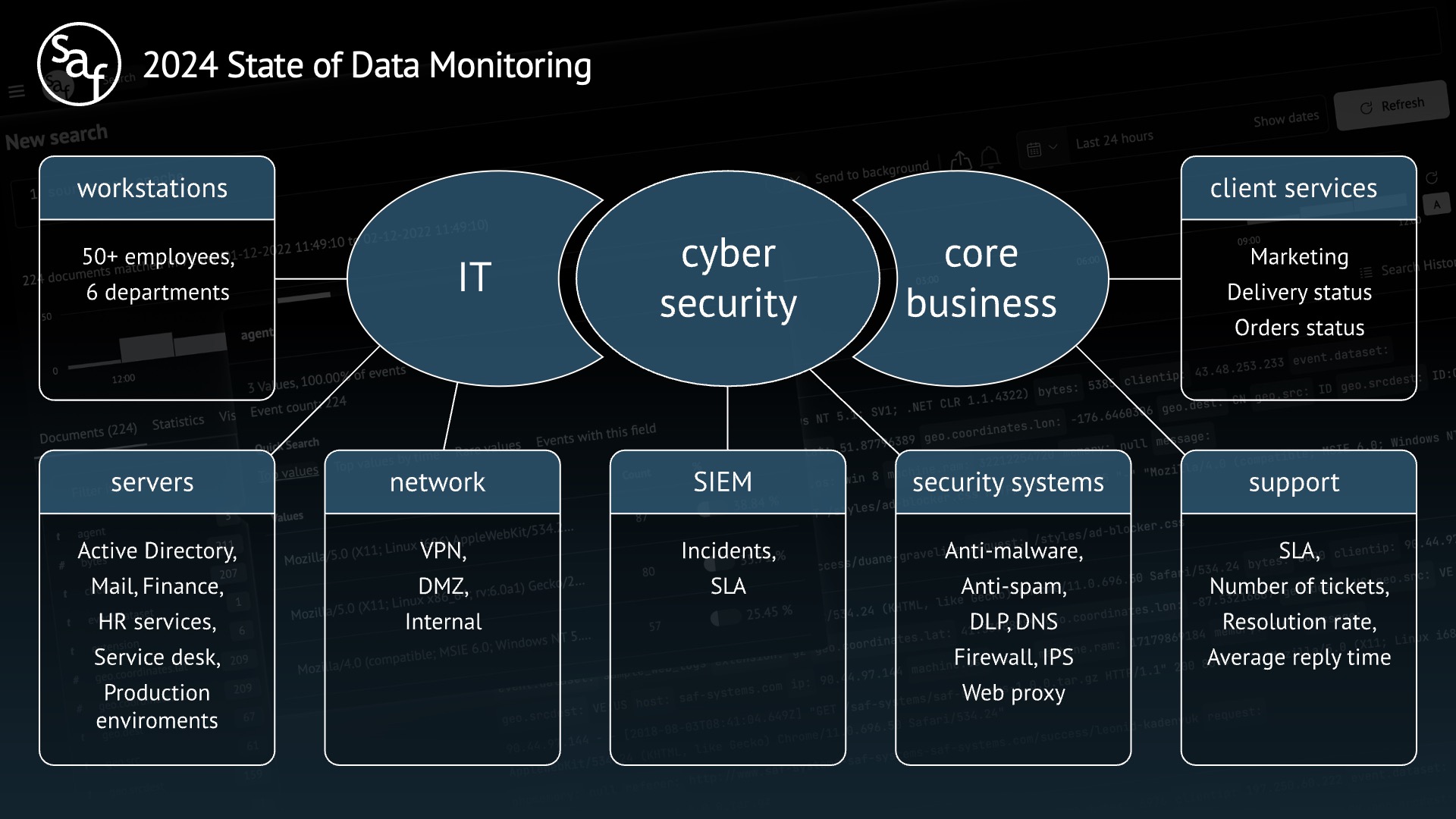
Company infrastructure
To further immerse you in the company, let's take a closer look at its detailed infrastructure.

Let's be in the role of employee
To understand how the Cybersecurity Bundle can help a company, let's put ourselves in the shoes of a Jolly Meal employee.
One beautiful (or not very beautiful) day, we receive a message about a critical event in the Incident Manager. What happened next and how was this problem solved within the SAF Cybersecurity Bundle? Let's find out in the video.

Summarize
-
-
The Inventory module gave us complete information about users, which helped us investigate the incident.
-

Throughout the corporation's existence, it will face cybercriminals and cyber attacks of varying complexity. Don't delay protecting your company - start using SAF today.
If you are interested in the Cybersecurity Bundle, you can contact us to discuss the details 🔥